
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 헬레나크로닌
- db
- 나만의주식5법칙
- 중용
- 비밀번호변경
- delete
- Django
- 옹졸함
- 꼭읽어봐야할책
- 성선택
- 다산의마지막습관
- ChatGPT
- 네인생우습지않다
- MySQL
- 클라우드
- linux명령어
- Python
- git 업로드
- 독후감
- 지방사람이보는서울사람
- Face Detection
- Git
- OpenCV
- 서울로가자
- 일일투자금액
- todolist
- 훌륭한모국어
- php
- 공작과개미
- UPSERT
- Today
- Total
목록분류 전체보기 (222)
Terry Very Good
 [DB/SQL] Left JOIN이란, 그리고 값이 더 많아지는 경우= 주의할 점( LEFT OUTER JOIN )
[DB/SQL] Left JOIN이란, 그리고 값이 더 많아지는 경우= 주의할 점( LEFT OUTER JOIN )
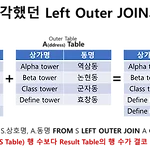
최근 소상공인 데이터 가공을 위해 LEFT OUTER JOIN을 쓰던 중, 나와야 할 데이터보다 행 수가 더 많아지는 상황이 발생했고, 그 문제에 대해 깨달았다. 아래와 같이 생각했던 것이다. SQL문: SELECT S.상가명, S.상호명, A.동명 FROM S LEFT OUTER JOIN A ON S.상가명 = A.상가명 → 당연히 기준 테이블(S Table) 행 수보다 Result Table의 행 수가 결코 클 수 는 없는거 아니야? 간과했던 것이 하나 있었는데, 그 예시는 아래와 같다. => Outer Table에서 JOIN의 키가 되는 값이 중복해서 있다면, 데이터가 뻥튀기된다. 이럴 경우 DISTINCT or GROUP BY을 사용해서 중복된 값을 제거하던지 해야한다.
문자열 중 불용어를 처리한 단어를 사용 빈도 별로 딕셔너리형태로 저장하는 방법 stopword(불용어): 데이터 처리에 있어 쓸모없는 단어 # stopword(불용어): 데이터 처리에 있어 쓸모없는 단어 s = "Life is short, Art is long!" stopwords = ['is', 'so'] d = {} for w in s.split(' '): if w in stopwords: continue d[w] = d.get(w,0) + 1 print(d)
문자열에서 특정 단어가 몇 번 들어갔는지 알 수 있는 방법 s = "Life is short, Art is long!" punct = ',.' for c in s: if c in punct: s = s.replace(c, '') d = {} for w in s.split(' '): d[w] = d.get(w,0) + 1 print(d) >> {'Life': 1, 'is': 2, 'short': 1, 'Art': 1, 'long!': 1}
문자열에서 단어만 추출하는 방법 # 문자열에서 단어만 추출하는 방법 s = "Life is short, Art is long!" punct = ',.' for c in s: if c in punct: s = s.replace(c, '') d = {} for w in s.split(' '): print(w)
리스트에 있는 특정문자 전체 삭제하는 방법 # 리스트에 있는 특정문자 전체 삭제하는 방법 l1 = [1,2,3,4,1,1,2,4,5,7,8,9,8,5,7,9] # 전체 값 l2 = [1,9] # 특정문자(이 문자가 l1에 있으면 다 삭제하고싶음) l2 = [i for i in l1 if i not in l2] print(l2) >> [2, 3, 4, 2, 4, 5, 7, 8, 8, 5, 7]
for문을 간결하게 짜는 법 # for문 기본형 l1 = [1,2,3] l2 = [] for i in l1: l2.append(i**2) print(l2) >> [1,4,9] # for문 간결하게 쓰기 l1 = [1,2,3] l2 = [i**2 for i in l1] print(l2) >> [1,4,9] # for문 간결하게 쓰면서 i가 2일 때는 안쓰기 l1 = [1,2,3] l2 = [i**2 for i in l1 if i != 2] print(l2) >> [1,9]
시퀀스 3종세트 (1). list(요소치환가능) = [1,2,3] (2). tuple(요소치환불가) = 10, or (10,20) / (10)은 아니야 ,가 없으면 튜플X / 값이 바뀌지 않게 보호하기위해 치환 X (3). str(요소치환불가) > but str = str.replace('is','fs') 라는 식으로 바꿀 수 있음. 추가 list.append(40) list.extend([40,50]) list.insert(3,40) 삭제 list.clear pop(지정한 위치 값을 삭제하고, 값 취득) remove(리스트요소명) del() strip() = 문자양끝의 공백 제거 isdigit() = 문자가 숫자로만 이루어져있는지 시퀀스 3종세트는 공통적으로 1.색인 2.슬라이싱 3.연결(+연결) 4...