
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 나만의주식5법칙
- OpenCV
- Face Detection
- 네인생우습지않다
- MySQL
- 옹졸함
- linux명령어
- php
- 성선택
- 클라우드
- 서울로가자
- git 업로드
- 일일투자금액
- 독후감
- Git
- 지방사람이보는서울사람
- ChatGPT
- UPSERT
- 공작과개미
- 다산의마지막습관
- delete
- Python
- 꼭읽어봐야할책
- 훌륭한모국어
- 헬레나크로닌
- db
- todolist
- 중용
- Django
- 비밀번호변경
- Today
- Total
Terry Very Good
AI Embedding이란(임베디드와의 차이부터 필요한 이유, 언제 사용하는지까지, 싱클리 참조) 본문
1. 임베딩과 임베디드의 차이
- 사전적 의미: Embedding(문서편집 중 사진 등을 끼워넣는 행위, 어떤 위상공간에서 다른 위상공간으로의 동상 사상)
Embedded(내장형, 임베디드, 임베디드시스템: 특정 기능을 수행하기 위해 HW와 SW를 밀접하게 통합한 컴퓨팅 장치)
2. AI에서의 임베딩(Embedding, Embedding Vector)
- 의미: 텍스트(Word,Sentence,Document 기준)를 실수 벡터 형태(floating point 숫자들로 구성된 고정된 크기의 배열)로 표현한 결과물로, 사람이 직접 관찰하고 그 의미를 파악하기는 어려우나, 서로 다른 단어 또는 문서로부터 추출된 Embedding들 간의 거리를 계산하면 이들 간의 의미적 관계를 파악할 수 있다는 이론
- 예제: Embedding Projector(Tensorflow에서 제공하는 임베딩 시각화 Tool)에서 Word2Vec(임베딩 방법)를 통해 1만 개의 단어로부터의 임베딩 결과를 3차원 공간 상에 투사한 결과(Geographic 클릭 시 유사어인 gepgraphical, coordinates, map, location 등이 그 의미정 유사도를 기준으로 내림차순 나열되어있음)

3. Embedding이 필요한 이유
- 1차적: AI모델은 함수이며, input값으로 숫자만 입력 가능하기에, 텍스트를 AI모델이 이해할 수 있는 숫자 형태로 변형 필요
4. Embedding하는 법
- 과거: One-Hot Encoding(AI학습에 사용되는 단어모음배열 하나를 만들어두고, 각 단어는 숫자 인덱스를 부여하기에, 사람이 이해하기에는 편하나, embedding vector의 차원(벡터에 포함된 숫자의 개수)이 100K~1M으로 지나치게 커져 핸들링 어려움)

- 현재: Learned Embedding(단어간 의미적 유사성을 가지고 embedding vector 거리를 조절하여, 사람이 보고 이해하기 어렵지만, embedding vector의 차원이 384~1536정도로 매우 낮아 핸들링 용이)
>> OpenAI Embeddings API를 활용하여, 거대 LLM을 구동하는 데 필요한 컴퓨팅 리소스 없이도 적은 비용과 2줄의 코드로 Embedding 추출이 가능하다.
import openai
response = openai.Embedding.create(input="porcine pals say", model="text=embedding=ada=002")
#text=embedding=ada=002 모델 사용 시, 1536차원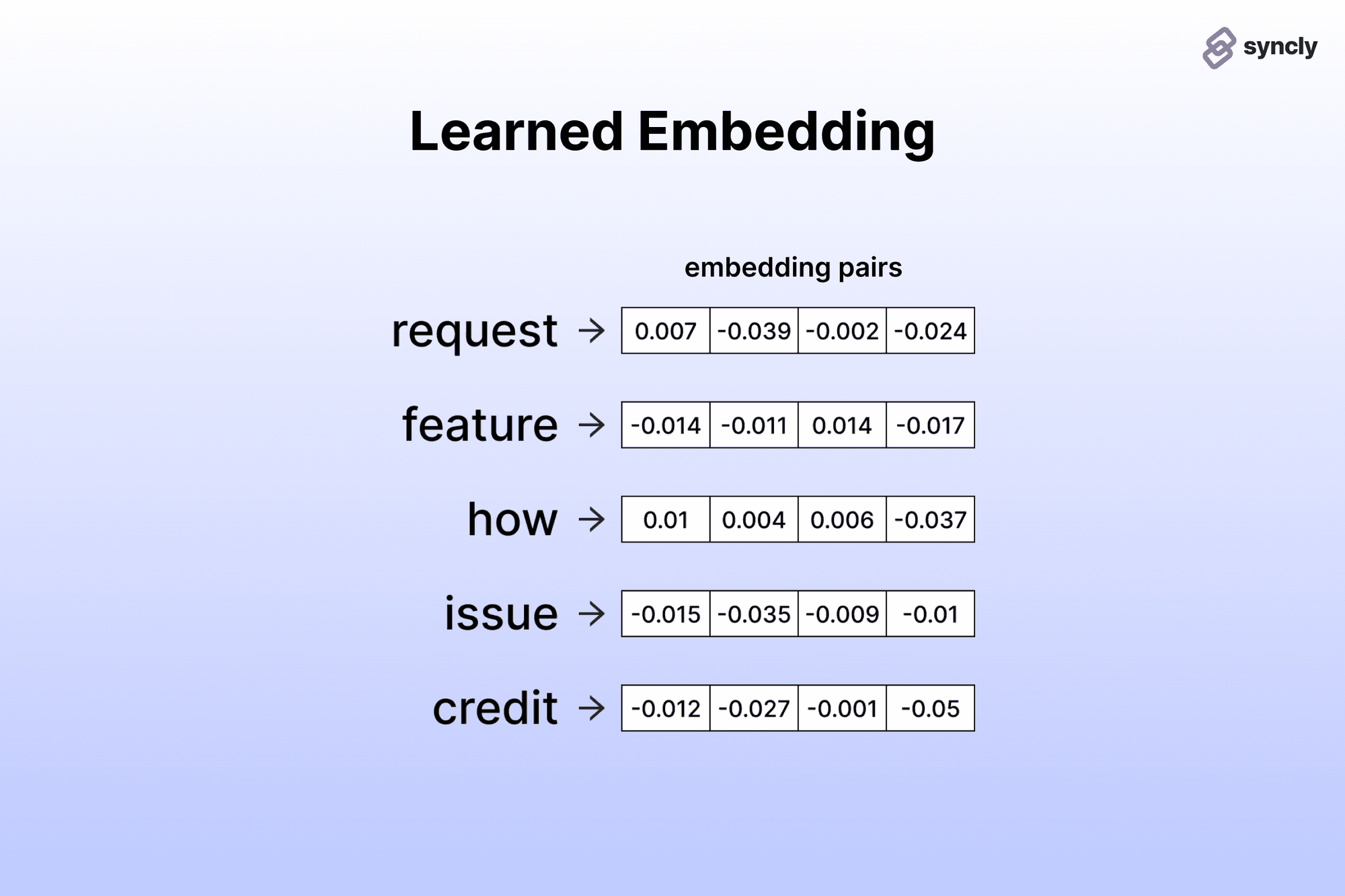
Embedding을 언제 사용해야하는지?
1. 의미 기반 탐색
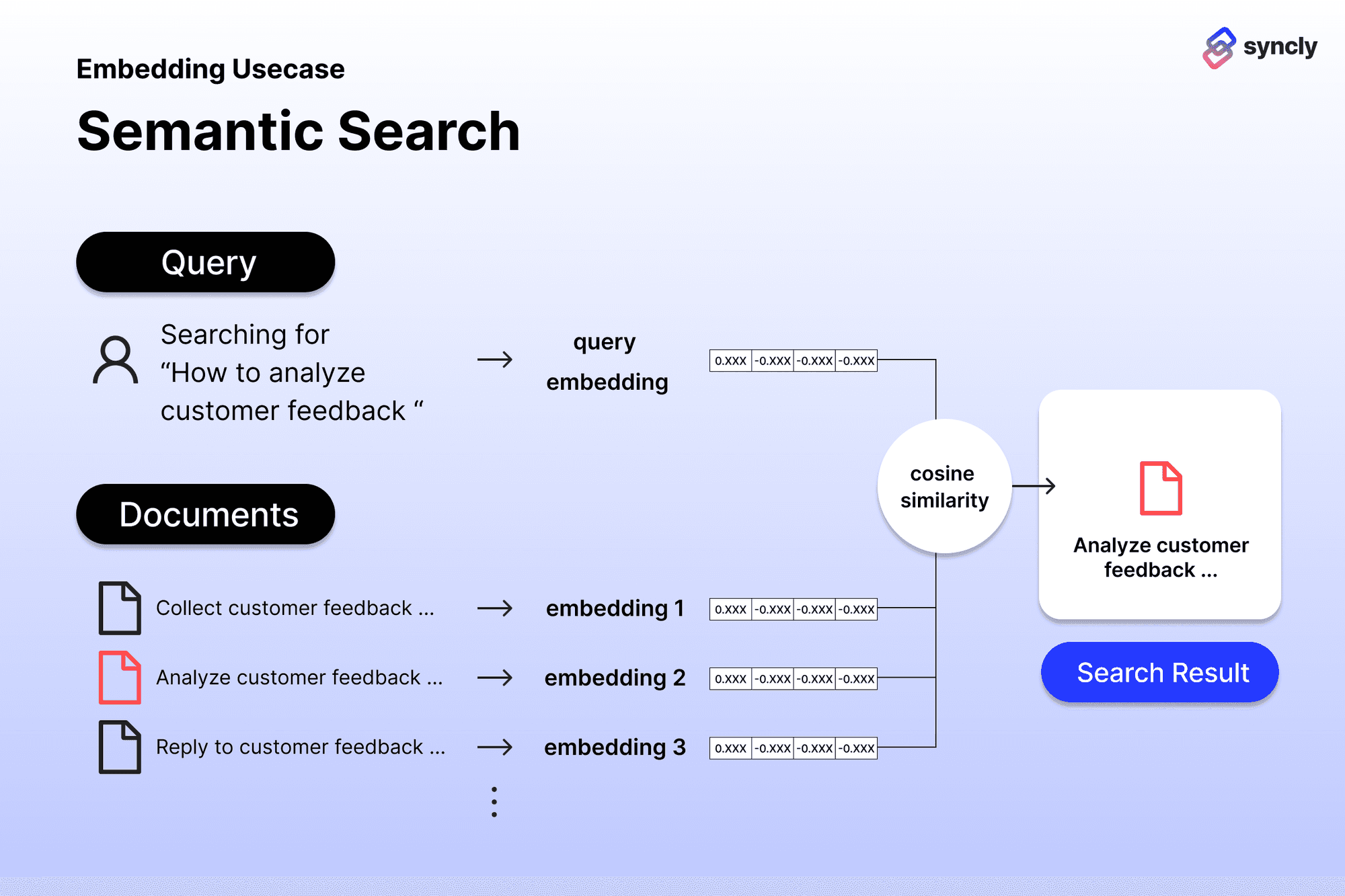
(A). Semantic Search(의미기반검색): https://github.com/openai/openai-cookbook/blob/main/examples/Semantic_text_search_using_embeddings.ipynb
>> 검색어(query)와 의미적으로 연관성이 높은 문서들을 찾아 제시해주는 기능
>> 질문한 query와 유사도가 높은 문서를 추천(아래 Recommend는 현재보고있는 문서의 embedding과 다른 문서들의 유사도가
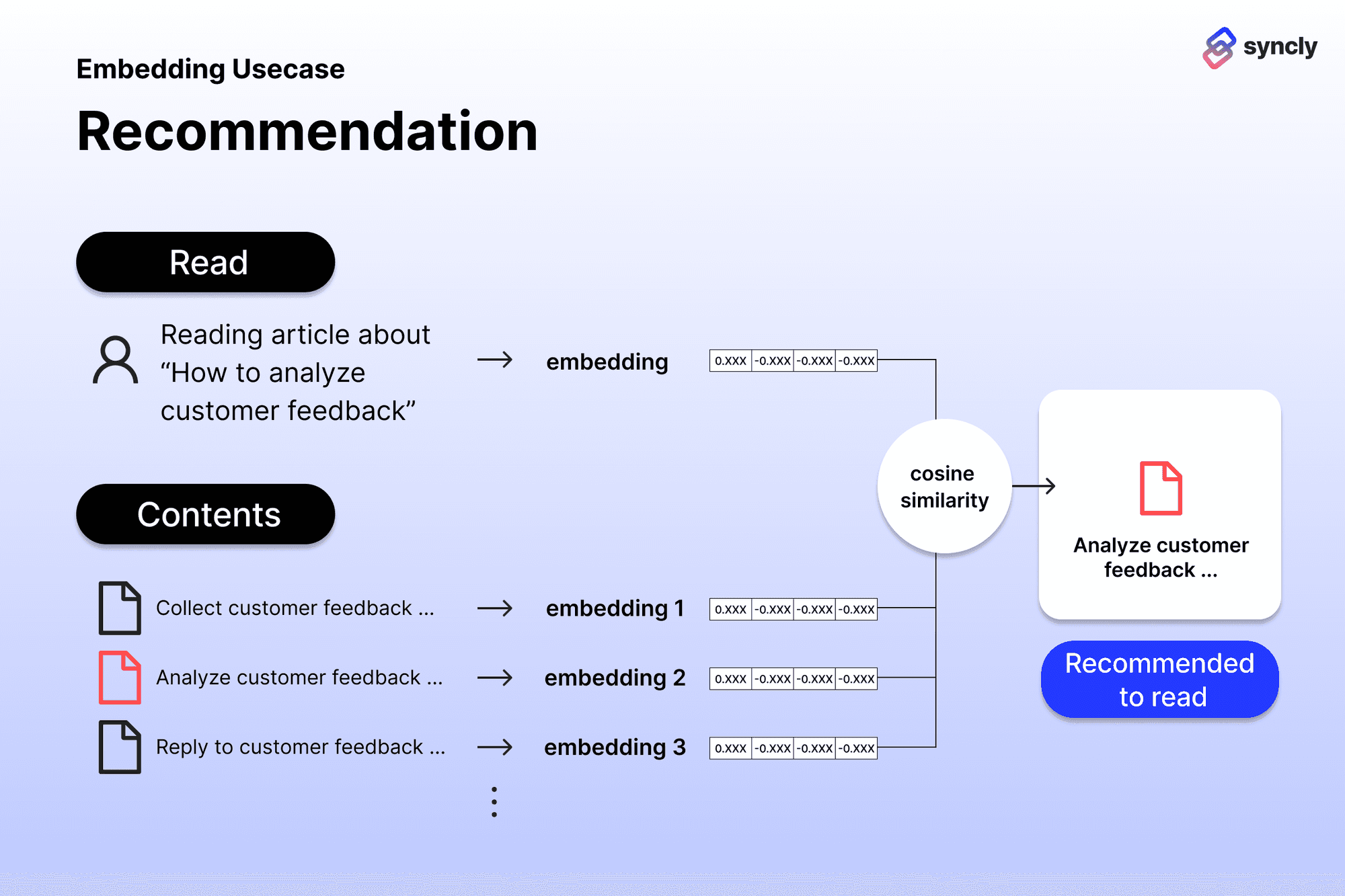
(B). Recommendation(추천): https://github.com/openai/openai-cookbook/blob/main/examples/Recommendation_using_embeddings.ipynb
>> 사용자가 현재 보고 있는 문서와 의미적으로 연관성이 높은 다른 문서들을 찾아 제시해주는 기능
(C). Clustering(군집화): https://github.com/openai/openai-cookbook/blob/main/examples/Clustering.ipynb
>>여러 문서들 간의 의미적 유사성을 바탕으로 몇 개의 그룹으로 묶어서 정리해주는 기능
>> 문서와 문서사이들의 Embedding 간의 거리를 계산해줘야 한다.
2. LLM 결과 생성을 위해 부가적인 정보 주입 시
- LLM은 인터넷 상에서 검색 가능한 공개된 정보에 대한 일반적 지식은 있으나, 개개인만 가지고 있는 비공개 정보에 대한 지식은 없음 > LLM으로 본인이 가지고 있는 정보와 연관된 결과물을 기반으로 어떤 질문에 대한 답을 출력하고자 한다면, 개인의 비공개 정보가 담긴 텍스트를 LLM의 Prompt에 함께 포함시켜 요청해야 함
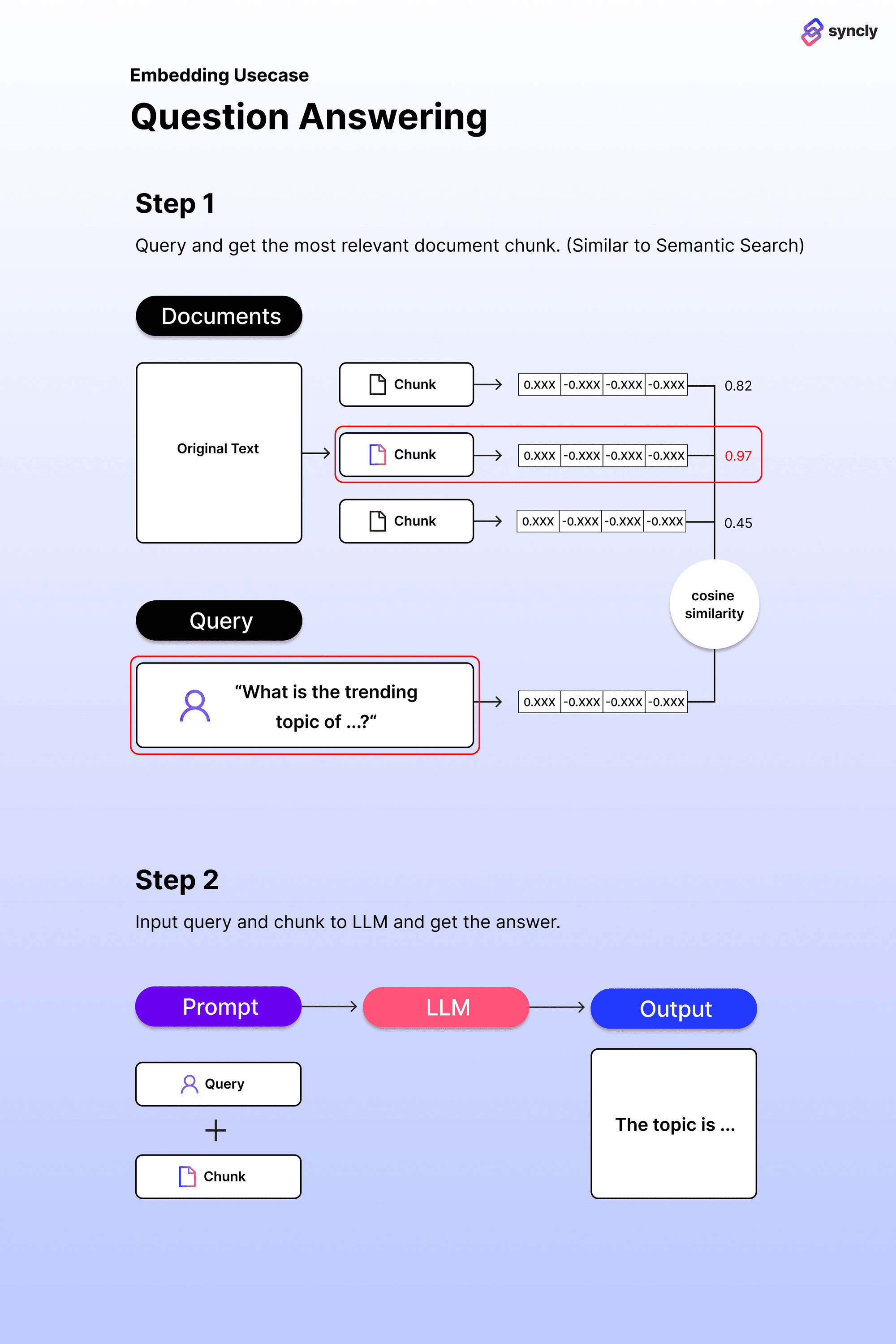
- 그러나, LLM서비스들의 경우 Prompt에 추가될 수 있는 텍스트 길이(토큰 수) 제한으로, 개개인의 비공개 정보가 텍스트 길이가 책 한 권 수준으로 길다면, 이를 미리 여러 chunk(덩어리)로 쪼개 놓고 이들 중 주어진 질문과 가장 연관성이 높은 chunk만을 골라서 prompt에 추가해야 함.
- chunk는 별도의 저장소에 저장한 뒤, chunk embedding을 통해, 원하는 내용의 유사도와 가장 가까운 chunk를 불러와 질문과 함께 LLM prompt에 요청(https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb)
- LLM은 한 번 입력받은 정보를 기억하지는 못하기 떄문에, 결과를생성하고자 할 때마다 본 과정을 계속 반복해야 함(stableless). EKfktj, Vector DataBase를 활용(SQL 등으로 표현된 query에 대해 정확하게 매칭되는 결과물을 추출하는 것이 아니라, query 또한 embedding형태로 표현되어있고, 유사도가 가장 높은 embedding을 가지는 데이터를 추출하는 방식을 지원한다(따라서, 512차원의 embedding을 요구하고, 10,000개 이상의 emnedding 개수라면 Vector Database 활용 고려, https://github.com/openai/openai-cookbook/blob/main/examples/vector_databases/chroma/hyde-with-chroma-and-openai.ipynb).
참조: Embedding이란 무엇이고, 어떻게 사용하는가? - 싱클리(Syncly) (today-gaze-697915.framer.app)
'신기술 습득 > IDEA&Tool&API' 카테고리의 다른 글
| ChatGPT API 사용할 때, 한 글자 한 글자씩 입력되게 하는 법(Stream True) (0) | 2023.06.25 |
|---|---|
| [ChatGPT] 3. AutoGPT 원리/요약/심화(왜 잘 안될까?) (0) | 2023.06.25 |
| [ChatGPT] 2. AutoGPT 원리/요약/심화(왜 잘 안될까?) (0) | 2023.06.25 |
| [Chrome Extensions] 생애 최초 크롬 확장 프로그램 만들기 (0) | 2023.04.12 |
| 인터넷 웹 브라우져에서 암호화된 M3u8 동영상 추출하는 방법(fetchv Video download) (0) | 2023.01.15 |

